
Sort-Based Iceberg Compaction Benchmark: Faster Spark Jobs, Lower Infrastructure Cost, No Tuning


Today, businesses struggle to process massive amounts of data. Performance and cost limitations make it impossible to unlock the full potential of their data and AI capabilities. Those limitations are caused by hardware.
In the future, data pipelines will be so fast and efficient that these limitations will disappear. Empowering companies to fully leverage their data, uncover transformative insights and AI model capabilities.
Dualbird is pioneering this future. We transform big data and AI infrastructure by redefining how hardware and software interacts. Eliminating barriers, boosting performance, and reducing costs.
We benchmarked DualBird against both vanilla Spark and state-of-the-art C++ accelerated Spark on a 100 GB sort-based Iceberg compaction workload. The results showed:
- ~12-20× faster Spark task execution
- 55-85% lower EC2 cost
- stable compaction cost across compute scaling ranges
- ~6× higher practical performance ceiling
First: what is Iceberg compaction, and why does it hurt?
When you ingest data into an Apache Iceberg table – whether it's streaming events, CDC from a database, or IoT telemetry – your ingestion pipeline writes lots of small Parquet files. That's fine for write throughput, but terrible for query performance. Too many small files means your query engine spends a disproportionate amount of time on metadata lookups and file-opening overhead, not actually reading data.
Compaction is the maintenance job that consolidates those small files into fewer, larger ones. Sort-based compaction goes a step further: it re-orders rows by meaningful sort keys (like day, user_id, event_time) so that query predicates can skip entire chunks of data without reading them, dramatically improving query speed over time.
The catch: sort-based compaction is one of the most compute-intensive jobs in a lakehouse. It reads, decodes, sorts, shuffles, and re-encodes potentially hundreds of gigabytes of Parquet data. On standard CPU-based Spark clusters, this is slow and expensive, and it only gets worse as your data volume grows.
A quick note on how Spark executes this: Spark breaks a job into small units called tasks. Each task runs on a single CPU core and processes one slice of data end-to-end: read - decode - sort - encode - write. The overall job can only finish when the slowest task finishes. That means a faster task = a faster stage = a faster job. DualBird's gains happen right at this fundamental level.
How DualBird works (the short version)
DualBird is a cloud-native custom hardware execution engine that accelerates Spark workloads underneath the existing Spark runtime. Instead of executing sort-heavy and shuffle-heavy operators entirely on general-purpose CPUs, DualBird offloads key execution paths – including SORT, JOIN, shuffle processing, and Parquet encode/decode – onto FPGA-based hardware acceleration running on AWS F2 instances.
Critically, it does this transparently. Spark still handles query planning, scheduling, and fault tolerance. Your pipelines don't need to be rewritten. You don't migrate to a new platform. DualBird integrates as a Spark plugin, zero code changes required.
What the benchmark found
We benchmarked DualBird against two baselines on a 100 GB sort-based Iceberg compaction job: vanilla Spark (unmodified, standard configuration) and state-of-the-art C++ accelerated Spark: the best CPU-based alternative, with carefully tuned EBS volumes, memory, and parallelism at each cluster size.
The synthetic dataset mirrored a real-world denormalized event/log table: ~370 million rows, 64 mixed-type columns (numerics, timestamps, strings, UUIDs, JSON blobs), with realistic null ratios and ZSTD level 3 compression – Iceberg's default.
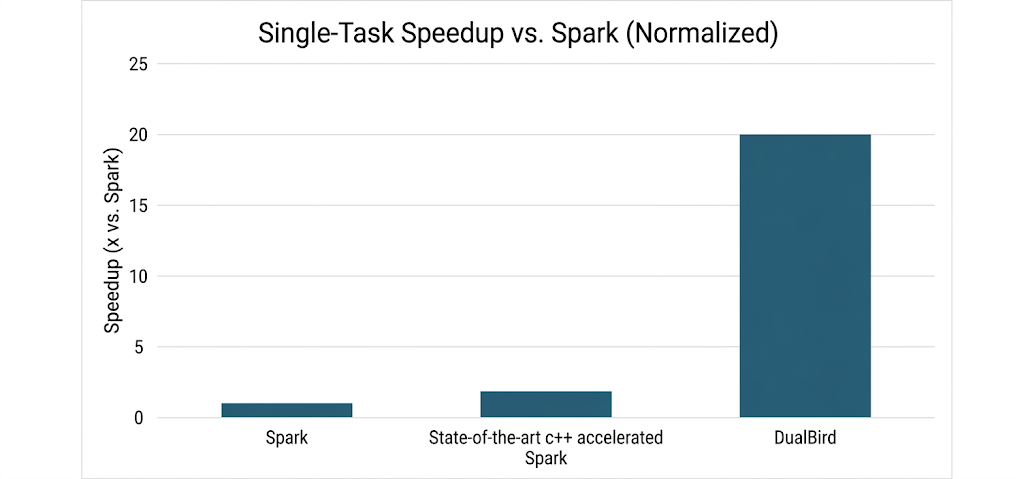
Single-task speedup. DualBird delivers 12-20× faster single-task execution compared to vanilla Spark, and an order-of-magnitude improvement over state-of-the-art C++ accelerated Spark. A 12-20× per-task speedup doesn't just make each task faster in isolation – it shortens every stage in the job, reduces tail latency from straggler tasks, and means you need far fewer tasks running in parallel at the same time, which frees up memory per task and makes disk spills essentially disappear.
Cost per terabyte compacted. This is where the economics really diverge. The structural issue with scaling CPU clusters: adding more nodes to chase performance increases the cost per terabyte compacted rather than reducing it. DualBird holds at ~$2/TB across a wide operating range; CPU-based clusters start at ~$6/TB and climb past $13/TB as cluster size grows. Part of the cost advantage comes from local NVMe storage built into F2 instances, which eliminates EBS volume costs entirely.
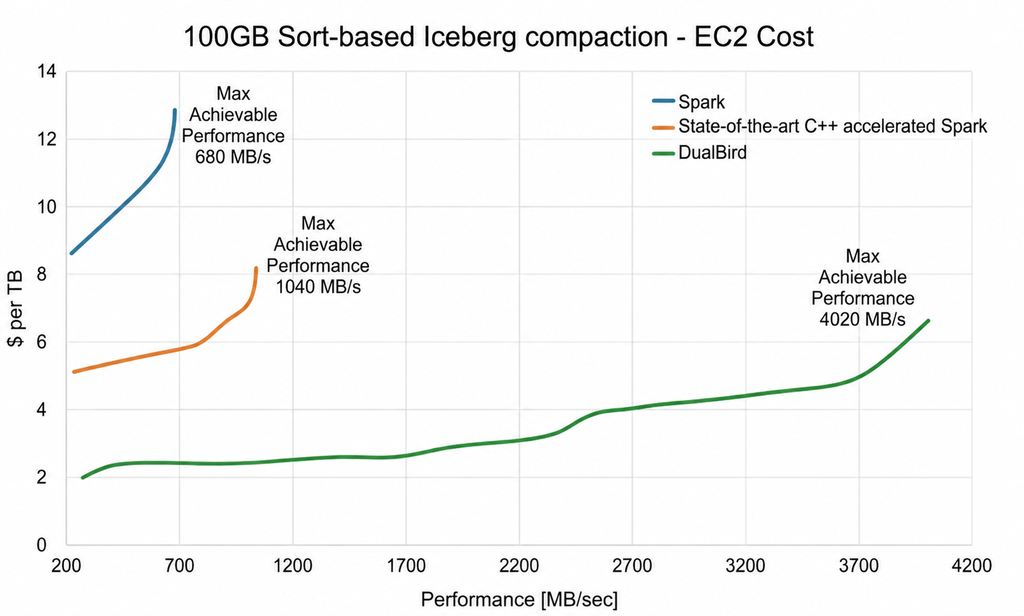
A higher performance ceiling. Every cluster architecture eventually hits a point of diminishing returns – a cluster size beyond which adding more nodes produces almost no additional throughput. CPU-based Spark hits this ceiling early on compute-heavy workloads because adding more cores can only increase parallelism; it cannot make an individual Spark task run faster once that task is limited by single-core CPU performance. DualBird pushes that ceiling out by roughly 6×. In practice, that opens up workloads that weren't practical before: near-real-time compaction at high ingestion velocity, aggressive sort-key strategies for better query skipping, and compaction of wide or string-heavy tables within tight maintenance windows.
The operational wins nobody puts in the headline
The performance numbers are compelling, but there's a second category of benefit that matters just as much in practice: the work your data engineering team no longer has to do.
Because DualBird offloads the Spark task execution that dominates CPU, memory, and shuffle cost, tens of Spark settings that normally require careful iterative tuning simply become irrelevant: executor sizing, CPU-memory ratios, parallelism settings. With far fewer concurrent tasks per executor, each task gets substantially more memory, so disk spills – a normal operating condition on CPU clusters – effectively disappear. The same memory headroom makes the system resilient to data skew, eliminating the straggler tasks and unpredictable runtimes that come with uneven partition sizes. And instead of evaluating instance families and sizing mixed fleets with EBS volumes, you standardize on a single instance type (F2). Cluster sizing reduces to one question: how many nodes?
For data engineering teams, this translates into hours and weeks of recurring tuning work that simply goes away, and meaningfully lower risk of incidents caused by spill-induced failures or runaway cluster costs.
The bottom line
The real opportunity is not just cheaper compaction. It is a better execution model for compute-heavy Spark workloads: faster tasks, fewer spills, less tuning, smaller clusters, and more predictable performance as data volumes grow. DualBird gives Spark teams a way to push past CPU scaling limits without rewriting pipelines or changing the Spark runtime they already use.
Transform your data infrastructure performance with a few clicks
Zero risk, zero effort, incredible results.


